Discrete Optimal Transport
Introduction
Optimal Transport (OT) in its basic form concerns how should one efficiently morph one distribution into another, and the work involved in the morphing is denoted as the distance between the distributions. You might recall the KL divergence as another way to compute distances, however there are some issues with KL, when the intersection of the supports is empty. In this article we I will explain OT for discrete distributions, which is how I first was introduced into the world of OT, specifically through the paper Siddhant and I worked on.
Vanilla Form
Given two discrete distribution and a cost matrix our objective can be written as:
Note: , is a vector of ones. This is a linear problem, we consequently we can solve this via linear programming. However, if we use methods like Simplex Method, they can sometimes take a lot of iterations to find the optimal. It also turns out that the solutions are sparse. From linear programming, we know that we should be searching for optimal solutions on the vertexs of the polytope. Instead what if we “smoothen” out the problem.
Entropic Regularization
Lets considered a modified objective
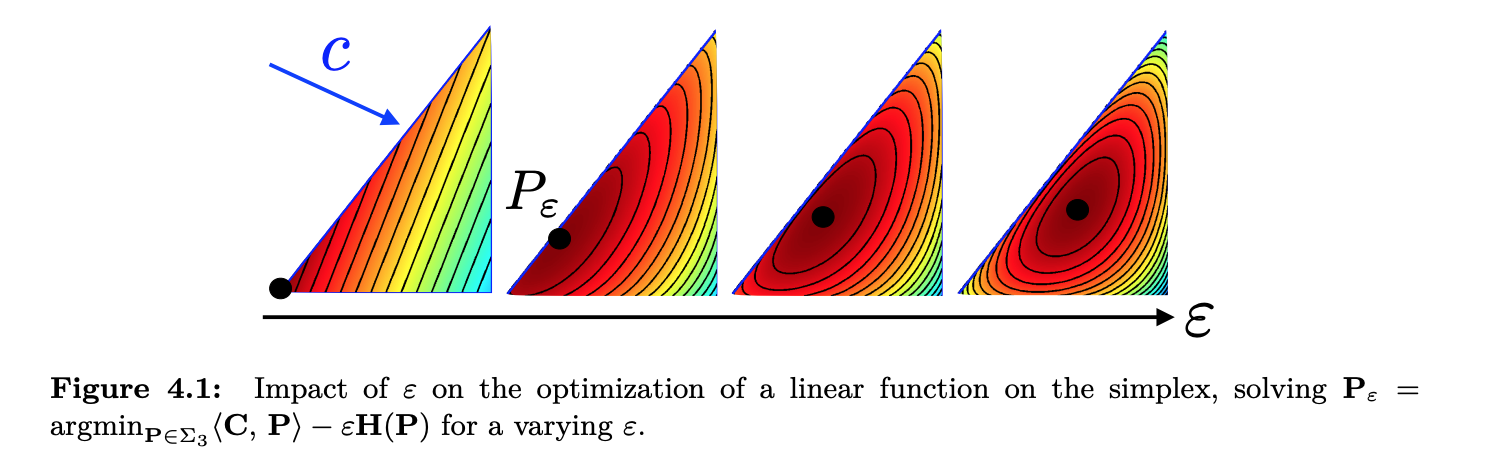
So we can see that as increases to we are just solving a max entropy problem. Also note that since entropy is convex, our objective still remains convex and we have an optimal solution.
Minimizing the Regularized Problem
If we take the Lagrangian we obtain
And from first order optimality we obtain
And of course we need to satisfy the marginals summing to . But if we look at the form of the equation for we see that the form of is
Where the matrix/vector exponentials are done element wise. This conveys that we need to find both the diagonal matrices such that satisfies the marginals.
Iterative Bregman Projections
We need to somehow find a way to optimize . First, lets look at our constraints. Specifically, the set of ’s that satisfy the rows summing to can be written as , and for the column constraint, . So the set we are interested is . We know there exists a solution to the transport problem (think about moving sand into a hole: Monge) so clearly is not empty. In addition, are closed convex sets. Therefore we can look at L.M. Bregman’s paper, The Relaxation Method of Finding The Common Point of Convex Sets and its Application to The Solution of Problems in Convex Programming. A condition for his theorem is we need to find a distance function that satisfies a list of conditions he outlines in the paper. One can show that the KL is a suitable function defined below
While this does exactly satisfy the precise requirements, it can be trivially modified (such as non negativity etc). Then we can define a projection as
We can find a closed form via introducing a Lagrange multiplier, and I will assume without loss of generalization
This implies that the KL projection onto is rescaling the rows of such that they sum to . If , then would appear instead which would imply column scaling. For row scaling, this is equivalent to left multiplying by a diagonal matrix, which is equivalent to recalculating . This yields us the Sinkhorn Knopp iterates, where one diagonal matrix is fixed and the other one is updated. Geometrically this is projecting onto either until convergence. Its not hard to show that the updates are
and for the columns
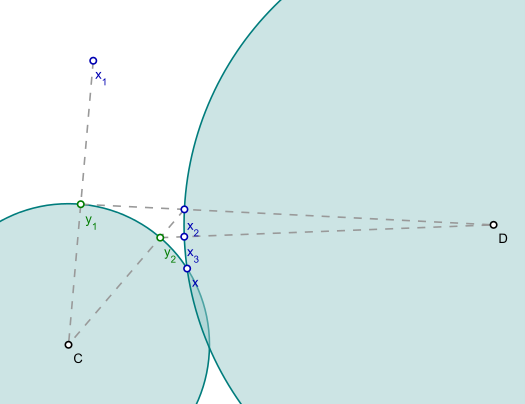
Geometrically, iterative projections look like the following figure (here the distance metric is Euclidian so the projects are straight, but they don’t have to be as in our case).
Other Related Works
Jason Altschuler has a cool paper [2], which introucdes an alternative variation on the iterates and shows better convergence by showing how the iterates decrease the following potential function.
Here, correspond to the diagonal elements:
References
[1] Computational Optimal Transport
[2] Near-linear time approximation algorithms for optimal transport via Sinkhorn iteration