Symmetries in Neural Networks
Intro
I read some cool papers this past few days that convey how to incorporate neural networks symmetries into optimizations or functions that operate on their weights.
Here are the papers:
So in this post I am going to mainly focus on the first two optimization papers. The premise is we have a function parameterized by .
The core idea behind these papers is realizing that depending on the network there might be some symmetries in . What do I mean by symmetries? Well what if I can manipulate without changing the output of . Let me show you a concrete example to illustrate this. Let’s take a network with just one hidden layer and ignore the bias term for now, and the activation is point wise non-linear, like ReLU.
I can create a group of permutations, where is a permutation that swaps rows of and the columns of . Note the below equation is just one way a group can interact with the weights, one could find more Groups.
Therefore, a different approach to optimization this network which is illustrated in Bo’s latest paper is to also search for . So to formalize this, let be all the parameters of the network. This just doesn’t apply to the two layer example, and it can apply to any network, but we will use the two layer one for simplicity. You need to find a group does operates on the weights without changing the function output, in the two layer case it could look like
Then we want to find a s.t.
Then we can do vanilla gradient descent on a batch of data
This is interesting because it means for a given set of parameter values at a time step , then we can manipulate them without it changing the output and loss value. That means searching over would be searching over a level set almost, and we want to find the point that largest gradient norm which is the steepest value. This is Figure 1 from Bo’s paper.
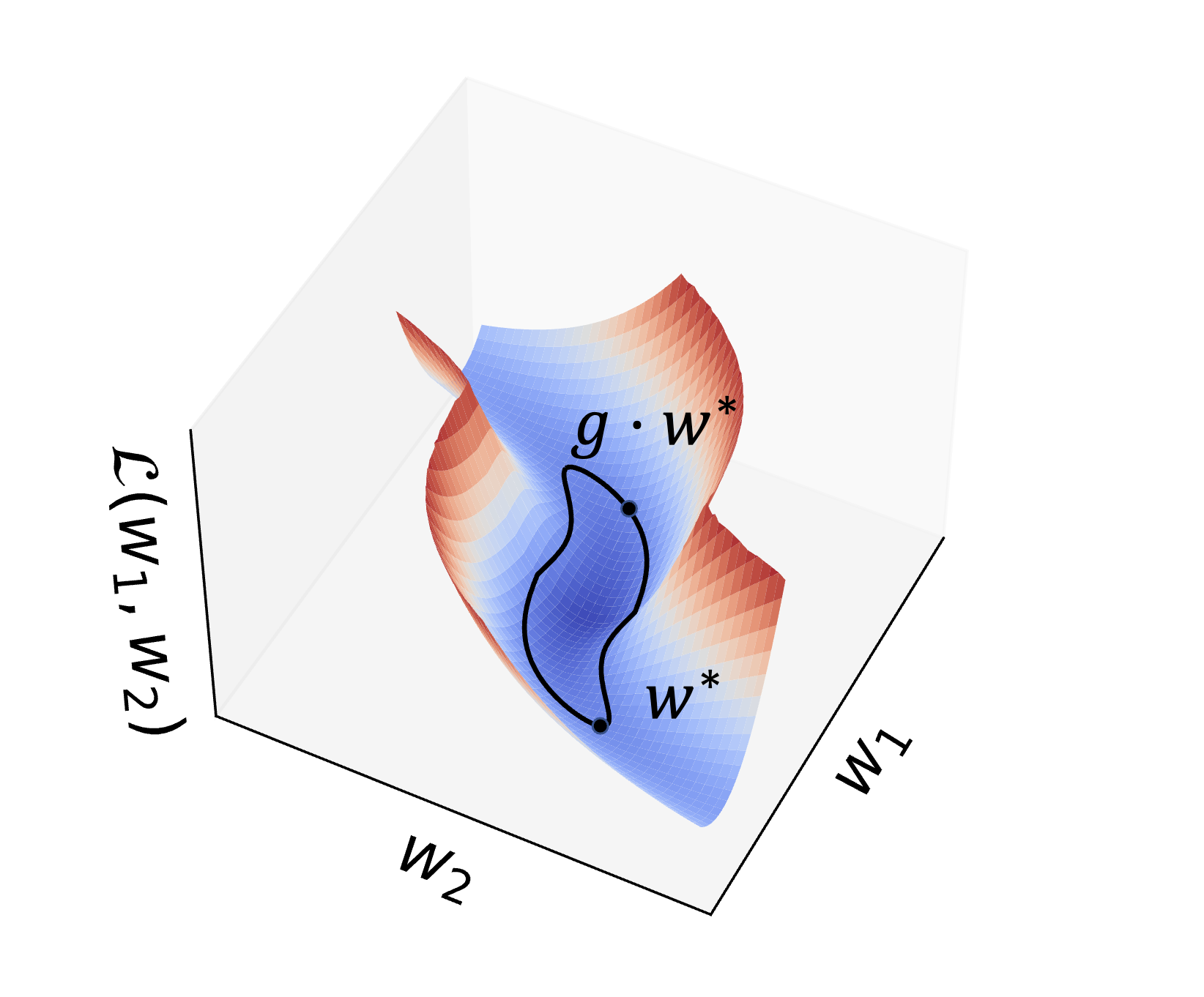
Now it can turn out that certain groups like the permutation group will have no effect on the gradient norm. In addition, the set of permutation matrixes isn’t smooth / continuous so we can’t use gradient based optimization to find the right permutation matrix easily. What is done in practice is use just group defined by , the group of exponentiated matrices. If you don’t recall, the matrix exponentiation operation is:
The cool property is is the inverse to . So we can make be pre/post multiplying by respectively. This allows us to do gradient optimization on while ensuring that we are within the group. In practice we take the first order Talor approximation and obtain respectively. This in general won’t guarantee the function value will be the same but the authors observe that the actual change is minimal, and they perform gradient descent to find that maximizes the gradient norm of w.r.t .
In general I find it interesting how we can find different parameterizations of the weights because we can really consider to be the new set of weights, and its interesting to think about how different parameterizations will affect the training trajectory.
Acknowledgments
I got in touch with Bo, and she gave useful feedback on this post!