Transformer
The Transformer has been a revolutionary step for NLP, and now image generation as well. It has surpassed other sequential models such as LSTMS. In this article I will be closing following the original paper Attention Is All You Need and explaining the inner working of this interesting model.
Overview
This model consists of an encoder and decoder. The encoder is composed of multiple of the grey blocks, and likewise for the decoder. More blocks, allows for a deeper semantic understanding. I personally visualize the encoder as a graph builder, one that finds many symantec connections between words and phrases,
and those relations along with past outputs are sent to the decoder to provide essential context / information for the task. The following diagram from the paper shows the encoder on the left and decoder on the right.
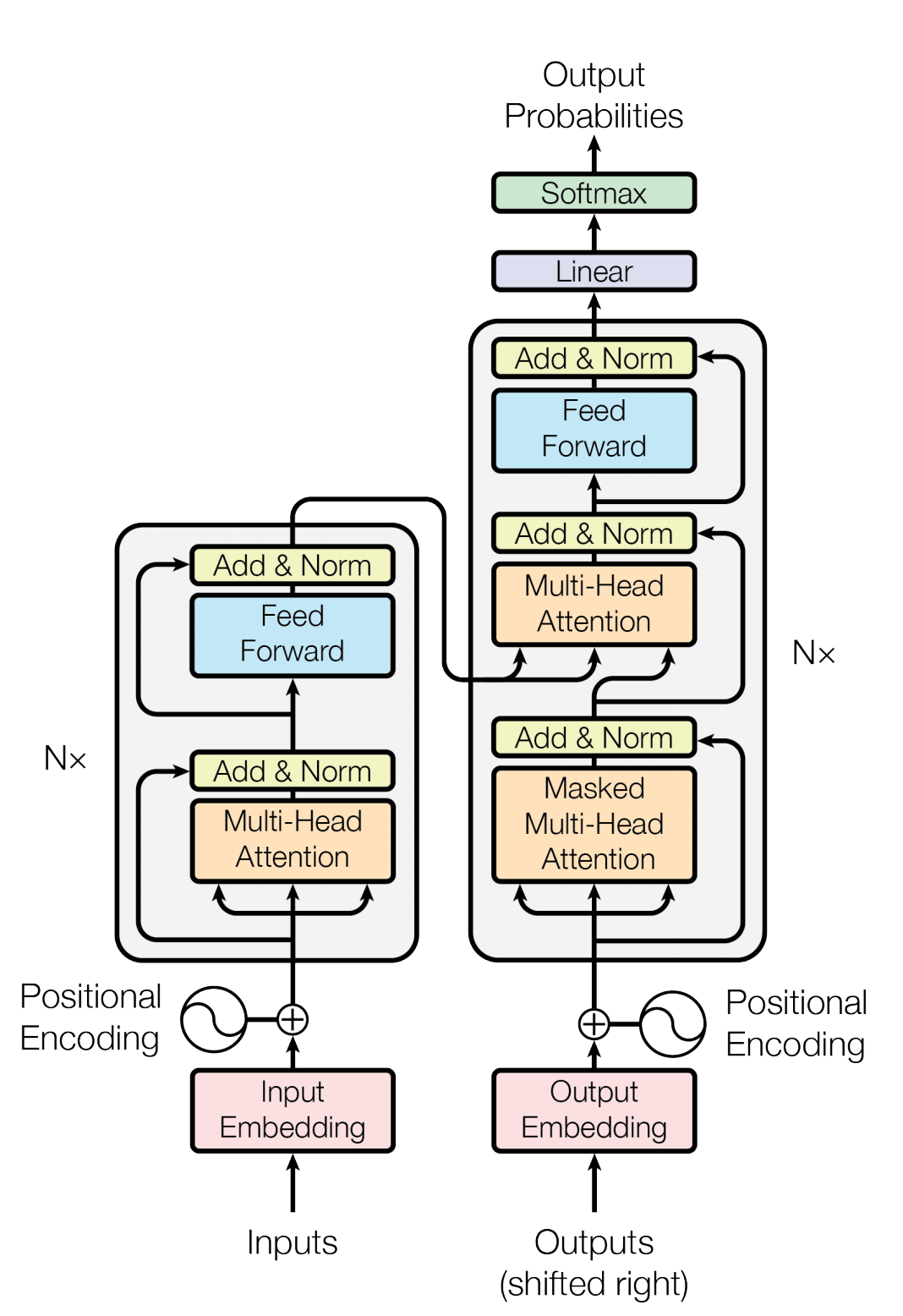
Input and Residual Connections
If you see the diagram, we see that the initial inputs are converted to an embedding, that converts the one hot encoding for each word into a compressed
semantic vector. This allows the model to gauge similarity between two words, which can not be done with one hot encoding. After the words are multiplied
by the embeddings matrix to produce the new input of embeddings, they are then added to a positional encoding matrix. The position of a word in a sentence
is an important metric, when trying to capture meaning. If there was no position encoding, the model parameters would have to capture the position of each word,
which puts more “stress” on the model, therefore it makes sense to add them beforehand. This leads us to residual connections. The following image shows what a residual connection in a regular neural network looks like.
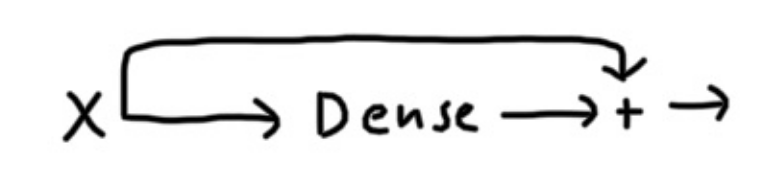
For Transformers, residual connections add the input vector to the output which helps preserve position and the original word itself.
Dot Product Attention
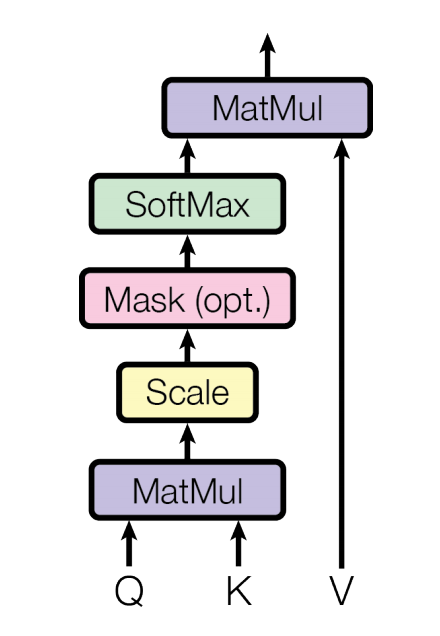
The diagram above is equivalent to the following equation, A is the attention function for the three matrices,
Q, V, K. Dot Product attention is core to transformers, it’s what allows for an efficient method of constructing connections.
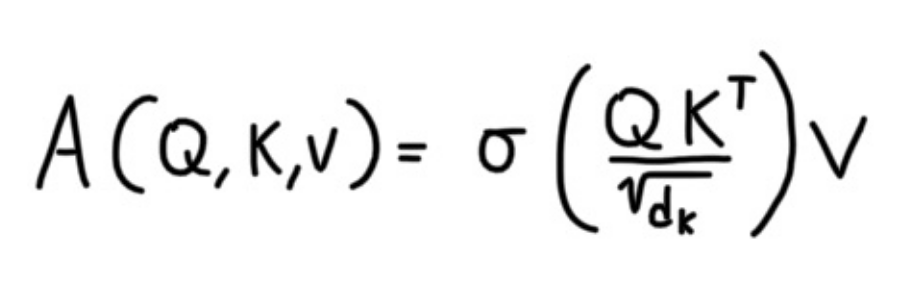
If we only had three input words, then Q, V, K would look like the following.
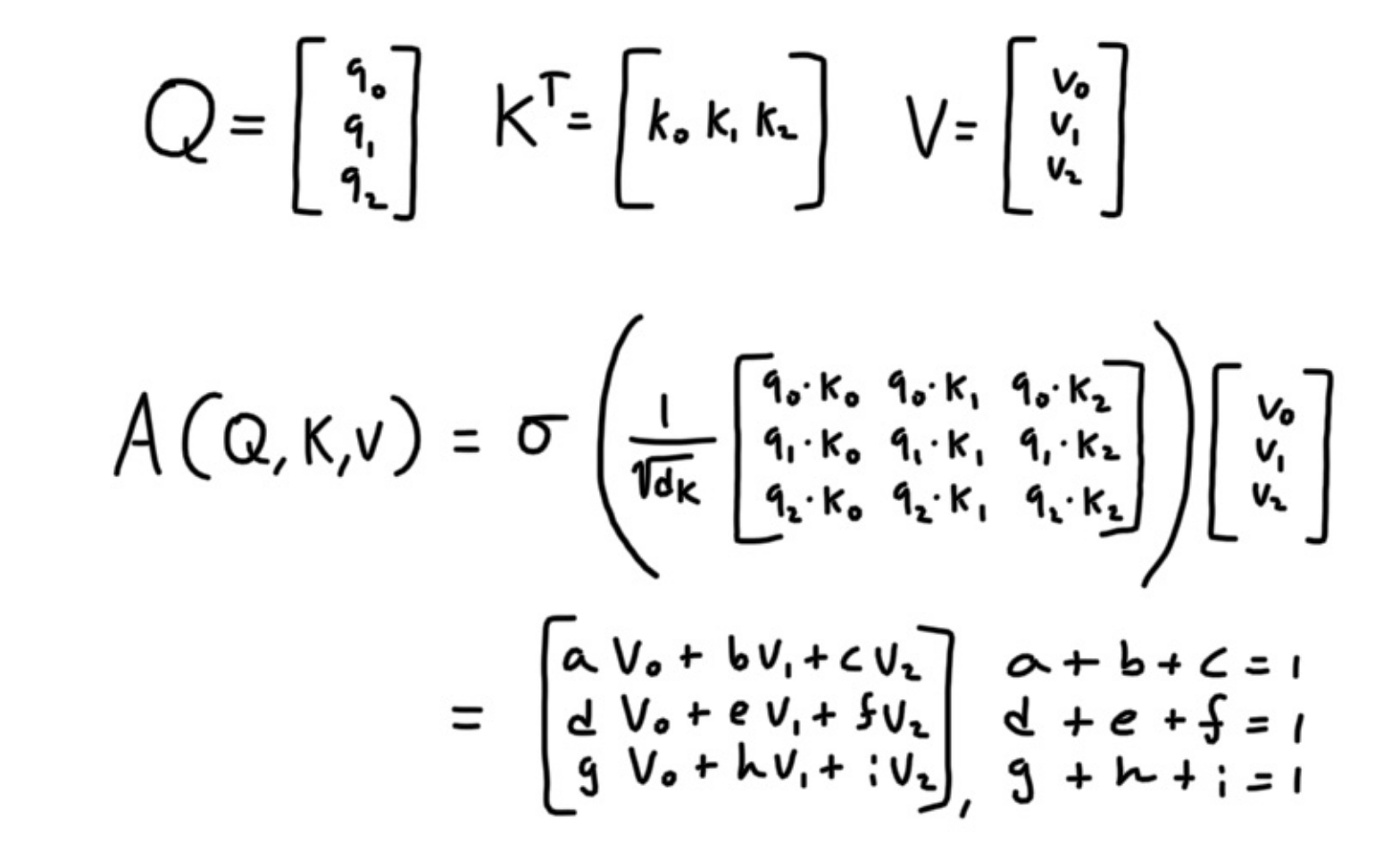
d_k is the size of q_i. We can see that this formula build connections among other words by summing value vectors, which are weighted,
so a strongly connected word would have the greatest influence into which region of the linear space that word’s vector resides in. Let’s see a visual representation of what one head does.
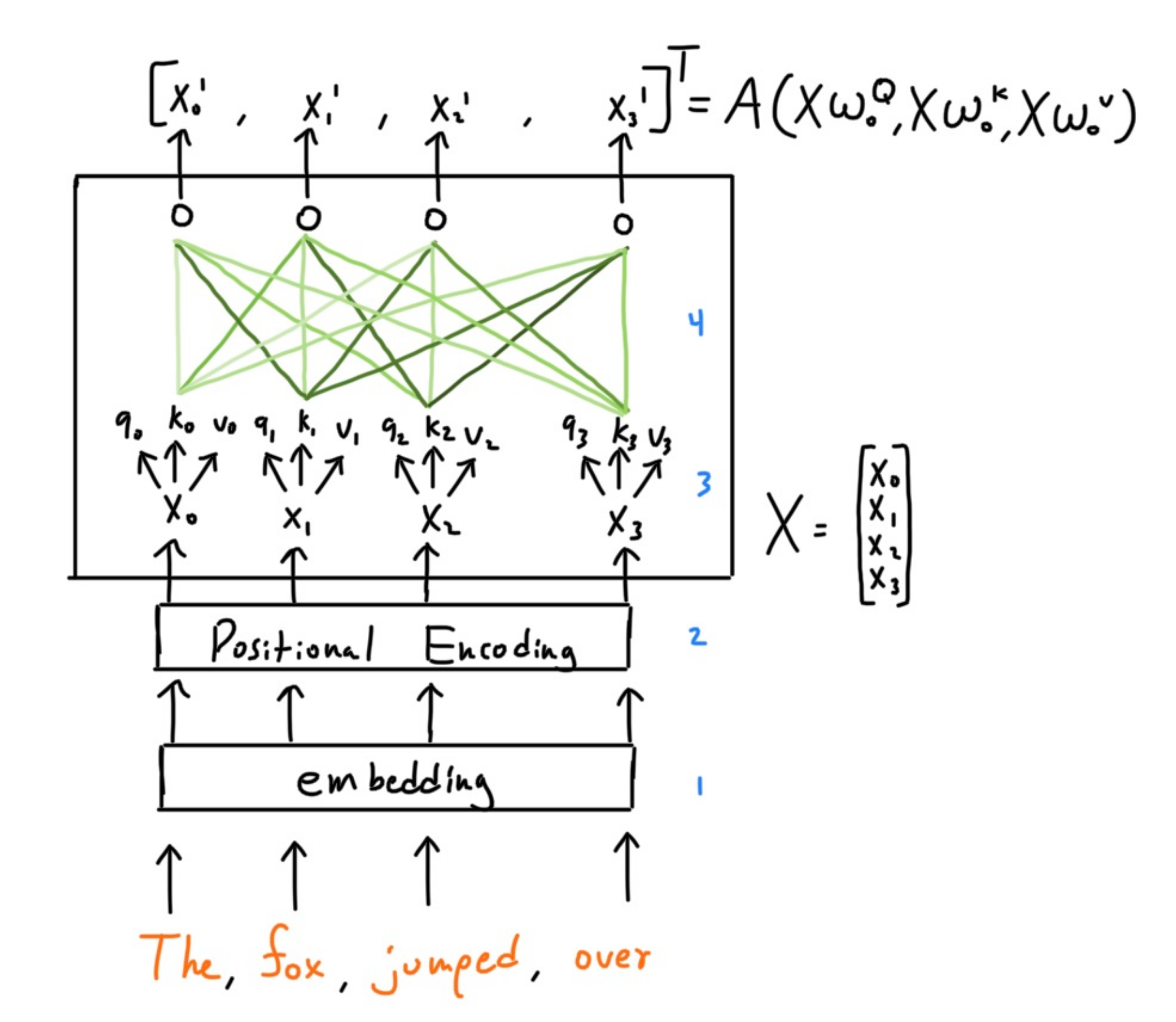
I randomly draw the connection strength, but you get the idea of how weighed the value vectors is equivalent to the connection strength.
Multiple Heads
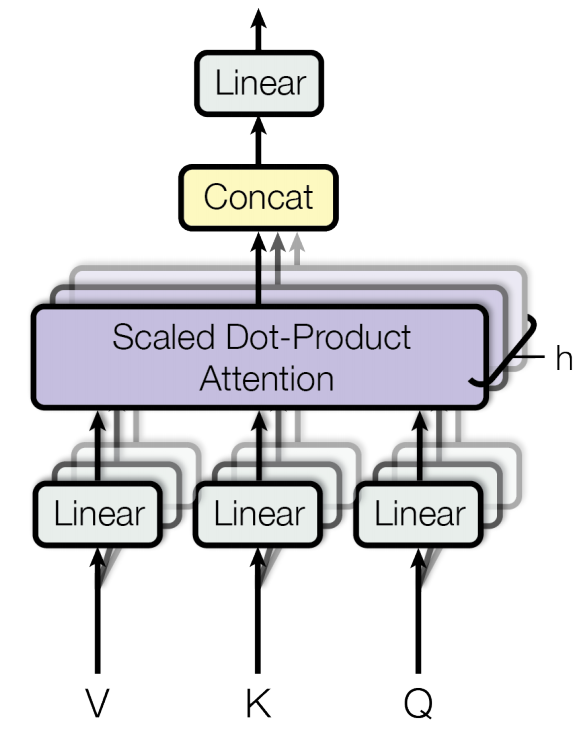
Since each head only has words with one set of Q,K,V, then one head won’t go too specific in how it wants to build connections between words. This is why the transformer has multiple heads, specifically the original paper used 8 heads, which means that for each head the attention module could see how each word relates to other words in 8 different ways. This allows the model to capture deeper semantic meaning, and it is really useful in higher level heads, where instead of just single words as in the first layer heads, the higher level heads look at relationships between collections of words. I made an illustration below to translate the diagram above.
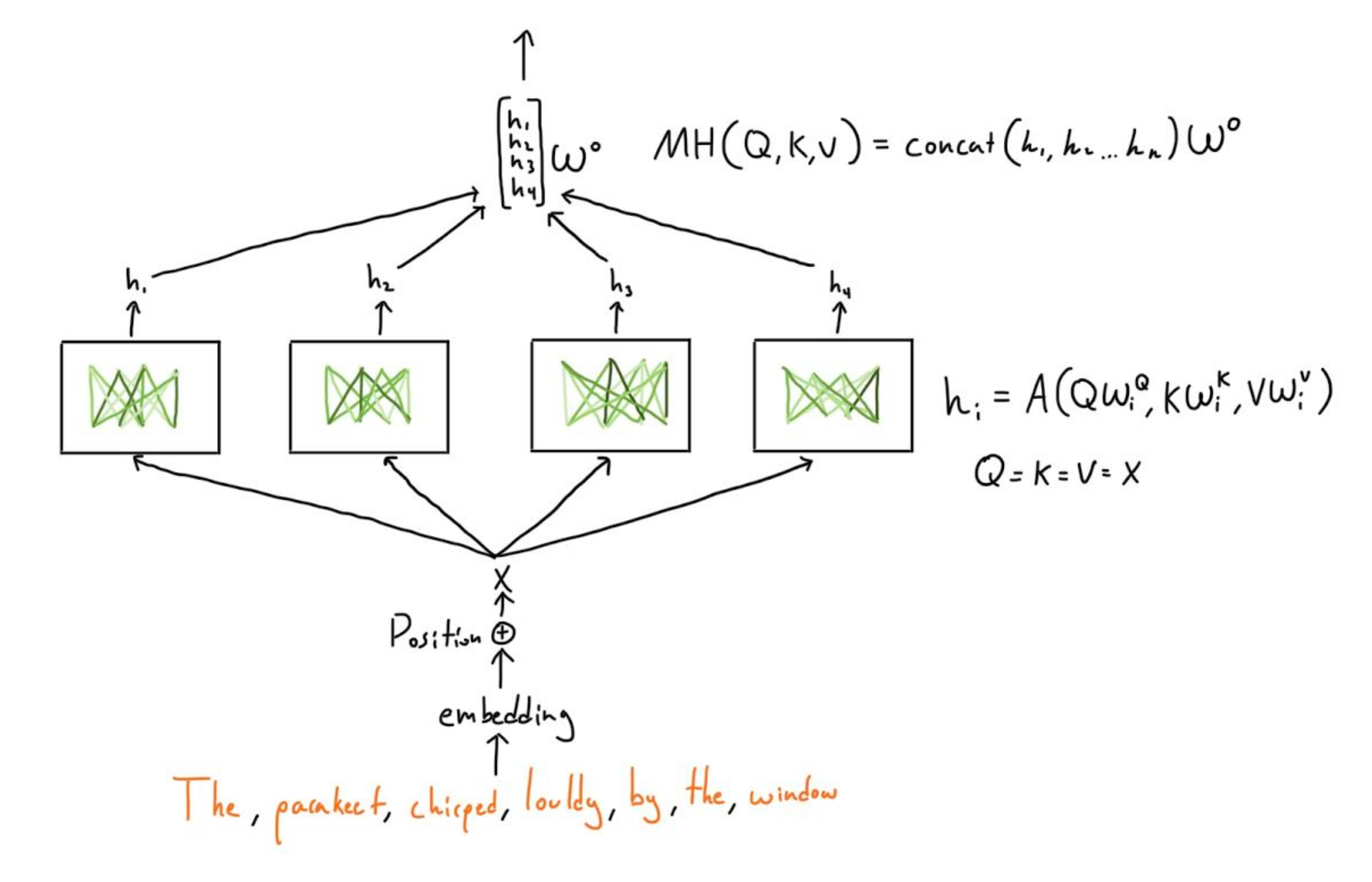
The parameters, WQ_i,WK_i,WV_i, W0 are unique for each block / layer.
The Rest Of Each Block/Stack
The output of the multihead is then added to the inputs (residual connection), and then sent a shallow neural network, which is unique for each block / layer.
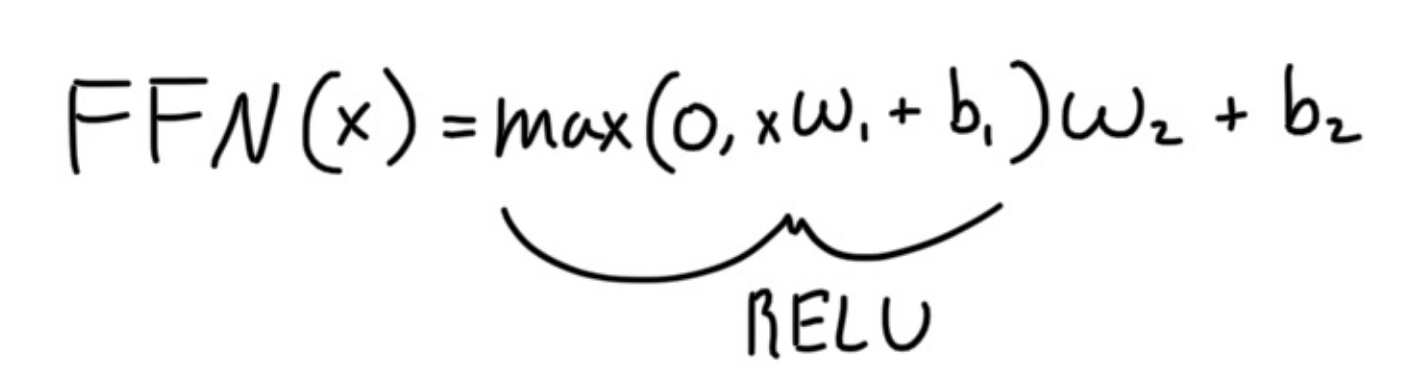
Furthermore, once added, the updated output is then processed by Layer Normilization which helps in stabilization and training time by evening out the gradient.
Decoder
The decoder is very similar compared to the encoder, but there are key differences. First, the decoder’s inputs are target outputs, but since it should not look ahead, masking is introduced. Observe the following diagram.
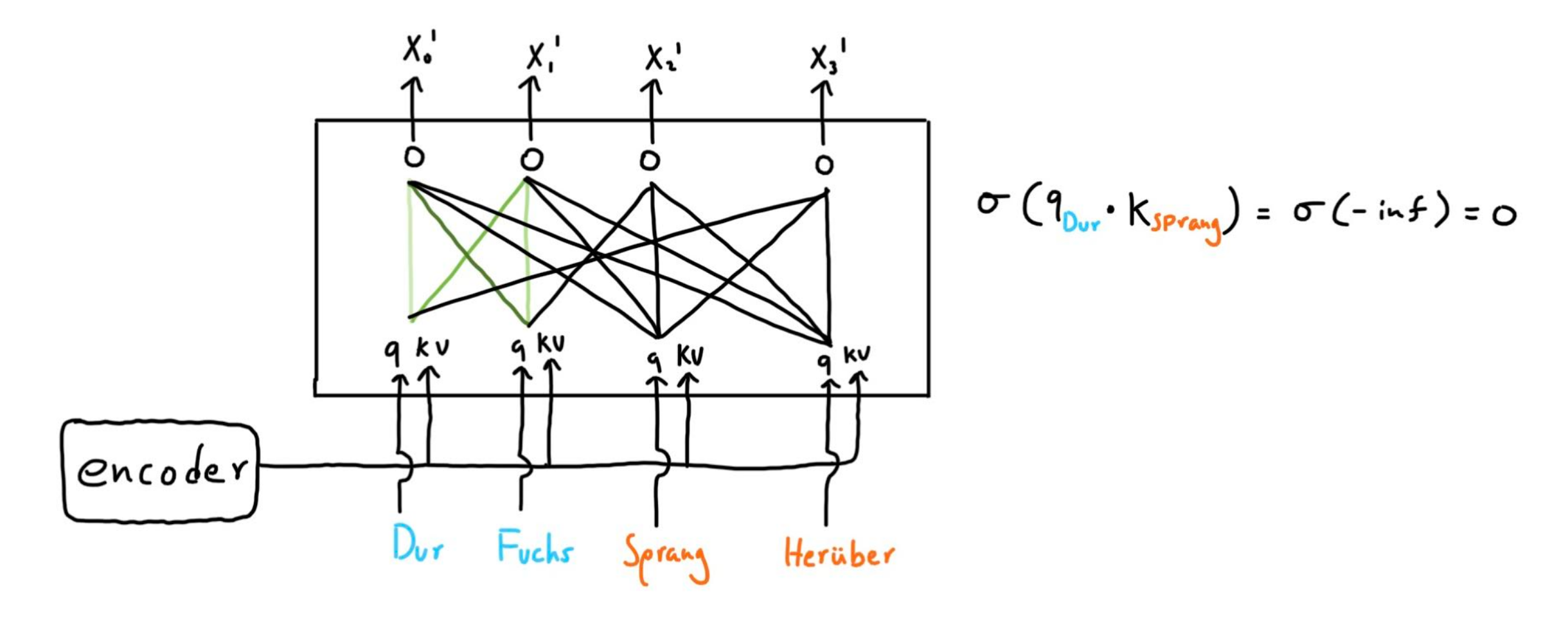
Here our task is english to german translation. The final encoder block’s keys and values are sent to the decoder, so that it can understand the context and relation of each word with respect to other words. Since the whole target output is fed to the decoder, we need to make anything that can reveal the part the decoder hasnt outputed yet. This is done by setting the softmax of any “future” word to any other word to 0.
References
https://arxiv.org/pdf/1706.03762.pdf
http://jalammar.github.io/illustrated-transformer/
https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)
https://arxiv.org/pdf/1607.06450.pdf
https://www.youtube.com/watch?v=5vcj8kSwBCY&t=832s