Reuse Can Be Useful
In my prior work, we encountered an interesting phenomenon: mixing different layers from various models can be beneficial for Mixture of Experts (MoE) merging. To my knowledge, this represents the first evidence that computations performed by different network layers can be effectively utilized at various positions within the overall computational graph.
This insight led me to consider whether we could apply a similar concept to a single network. Specifically, after pre-training, could we post-modify the network to enable layer reuse?
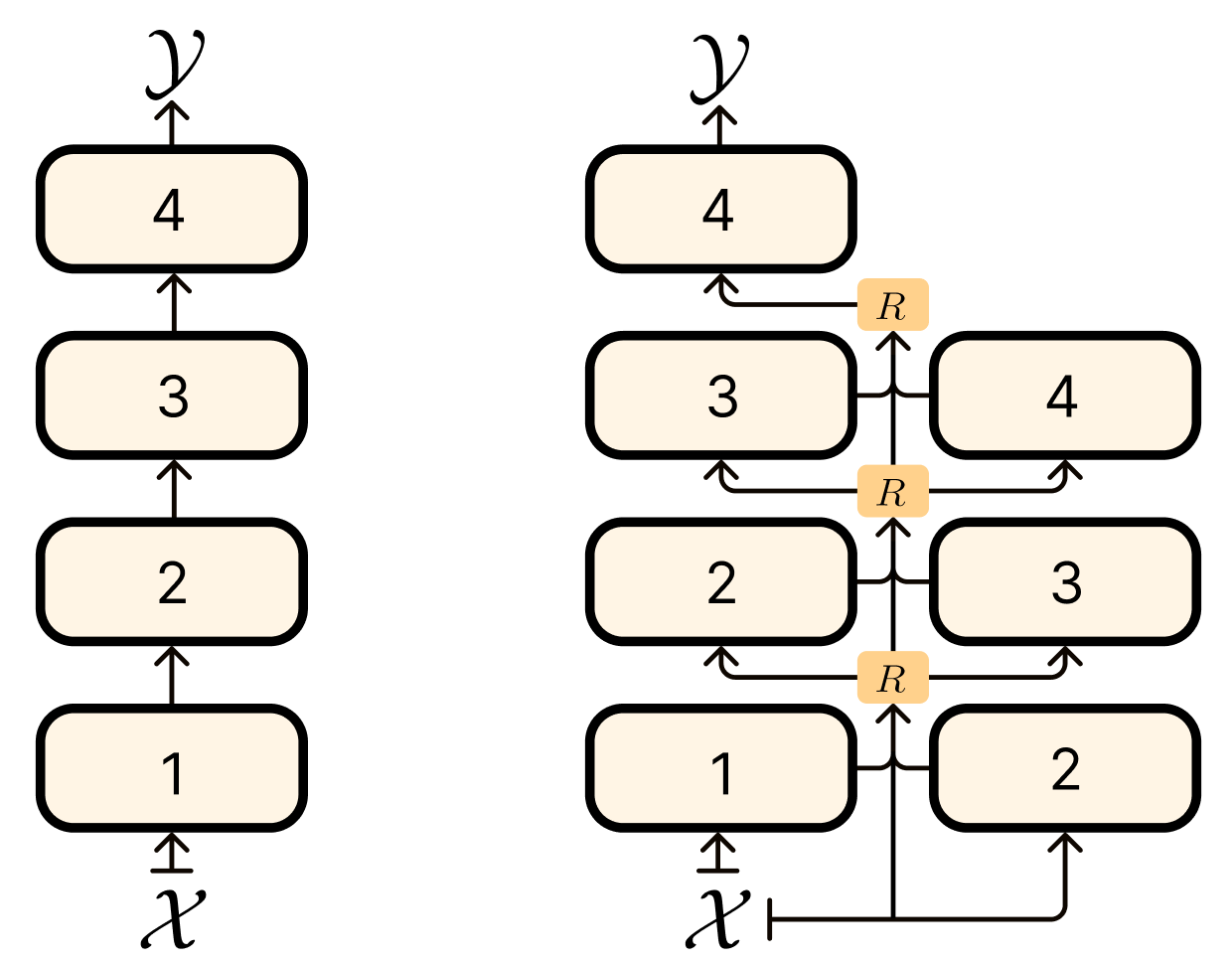
To test this hypothesis, I took the nanoGPT codebase from Andrej Karpathy along with a pretrained GPT2, then introduced the routers and only finetuned them on a new dataset TinyStories. This introduced 18,432 parameters to train. I use a typical routing function in a MoE model of the following form:
, where and is the number of tokens.
For more details, the router has no sparsity, and we introduce a bias +4 to initialize the model to be similar to layers following a sequential order. Here is the router code.
class Router(nn.Module):
"""Routes tokens to different blocks and combines their outputs using learned weights"""
def __init__(self, config, num_experts):
super().__init__()
self.router = nn.Linear(config.n_embd, num_experts, bias=False)
self.num_experts = num_experts
def forward(self, x, expert_outputs):
# x shape: (batch_size, seq_len, n_embd)
# expert_outputs: list of (batch_size, seq_len, n_embd) tensors
# Calculate routing weights
routing_logits = self.router(x) # (batch_size, seq_len, num_experts)
routing_logits[:, :, 0] += 4
routing_weights = F.softmax(routing_logits, dim=-1)
# Combine expert outputs
combined_output = torch.zeros_like(x)
for i in range(self.num_experts):
combined_output += expert_outputs[i] * routing_weights[:, :, i:i+1]
return combined_outputResults
| Method | CE Validation Loss | Perplexity |
| Baseline GPT2 | 2.384 | 10.85 |
| GPT-2 with Layer Reuse | 2.278 | 9.76 |
Future Interesting Directions + Related Work
It's interesting that layers show potential for reuse even without being explicitly trained for this purpose. A promising research direction would be developing methods to pretrain transformers so different layers can be dynamically deployed at various positions in the computational graph.
While
Looped Transformers and Universal Transformers explore similar concepts, they simply reuse the same layer. A more expressive approach would maintain multiple distinct layers that can be flexibly reused. The challenge lies in simultaneously learning both the layers and their routing patterns during pre-training—a difficult bilevel optimization problem that also plagues standard MoE training.
In addition, building on ideas from the
Coconut paper (which is quite innovative), we could potentially inject adapters or train models for continuous reasoning that doesn't just follow a fixed path. By investing additional compute, we could enable layer reuse and create more sophisticated pathways through the network architecture.
Code
Citation
@misc{pari2025reuse,
author = {Jyothish Pari},
title = {Reuse Can Be Useful},
year = {2025},
url = {https://jyopari.github.io/posts/reuse}
}