RL's Razor: Why On-Policy Reinforcement Learning Forgets Less
Idan Shenfeld, Jyothish Pari, Pulkit Agrawal
MIT
Paper: https://arxiv.org/abs/2509.04259
Abstract
We compare fine-tuning models with supervised fine-tuning (SFT) and reinforcement learning (RL) and find that, even at matched new-task accuracy, RL consistently forgets less. We investigate the cause and show that the degree of forgetting is not determined by the training algorithm itself, but by the distributional shift, namely the KL divergence between the fine-tuned and base policy when evaluated on the new task distribution. RL’s advantage arises because on-policy updates bias optimization toward KL-minimal solutions among the many that solve a task, whereas SFT can converge to distributions arbitrarily far from the base model. We validate this across experiments with large language models and controlled toy settings, as well as provide theory on why on-policy RL updates lead to a smaller KL change. We term this principle RL’s Razor: among all ways to solve a new task, RL prefers those closest in KL to the original model.
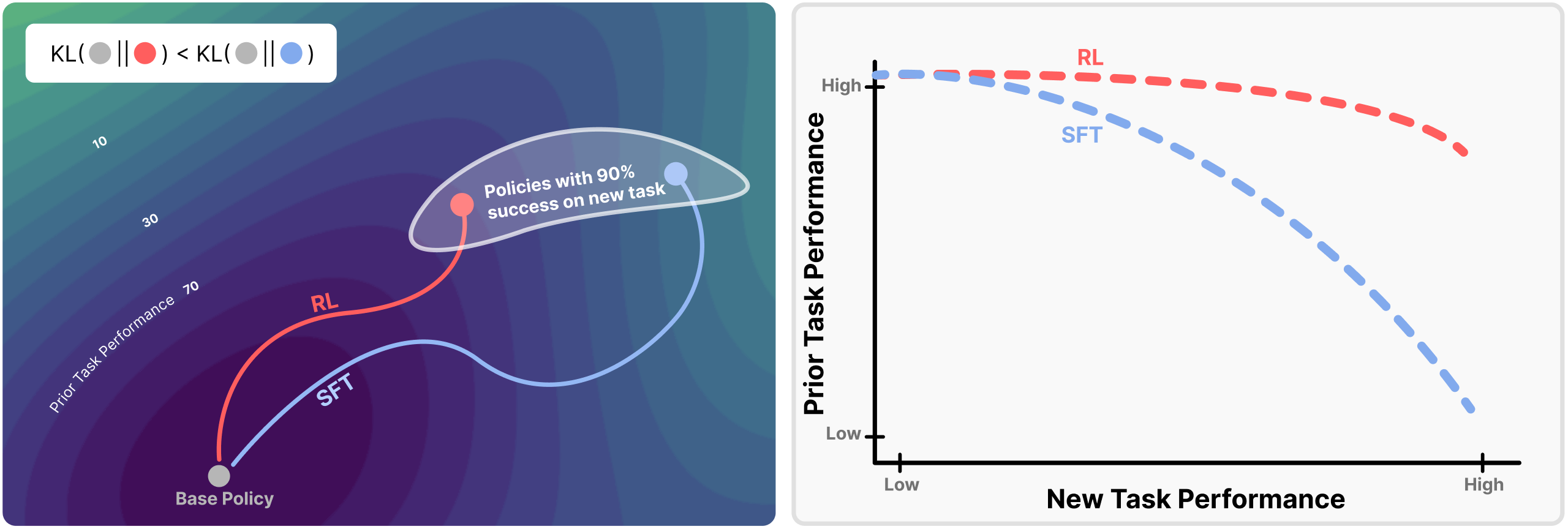
Reinforcement Learning Forgets Less than SFT
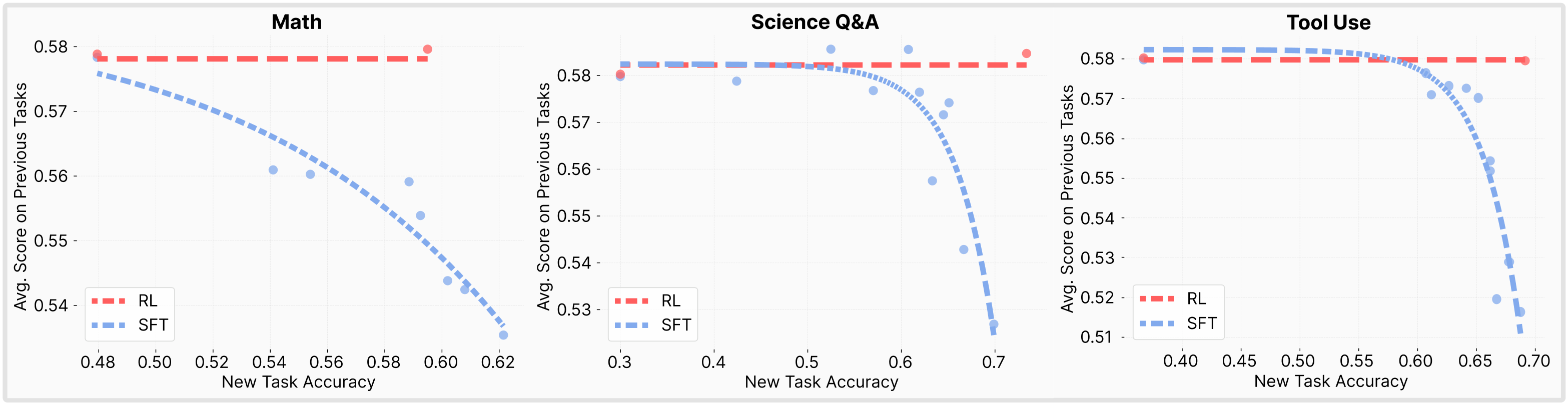
We compare the degree of catastrophic forgetting induced by SFT and RL. The comparison is carried out by training large language models on new tasks and then measuring how much their ability to perform previously acquired tasks is degraded. We plot the Pareto-frontier after training Qwen 2.5 3B-Instruct on each task with hyper parameter sweeps. Note how RL does not have the same level of catastrophic forgetting as SFT.
Smaller KL divergences lead to less forgetting
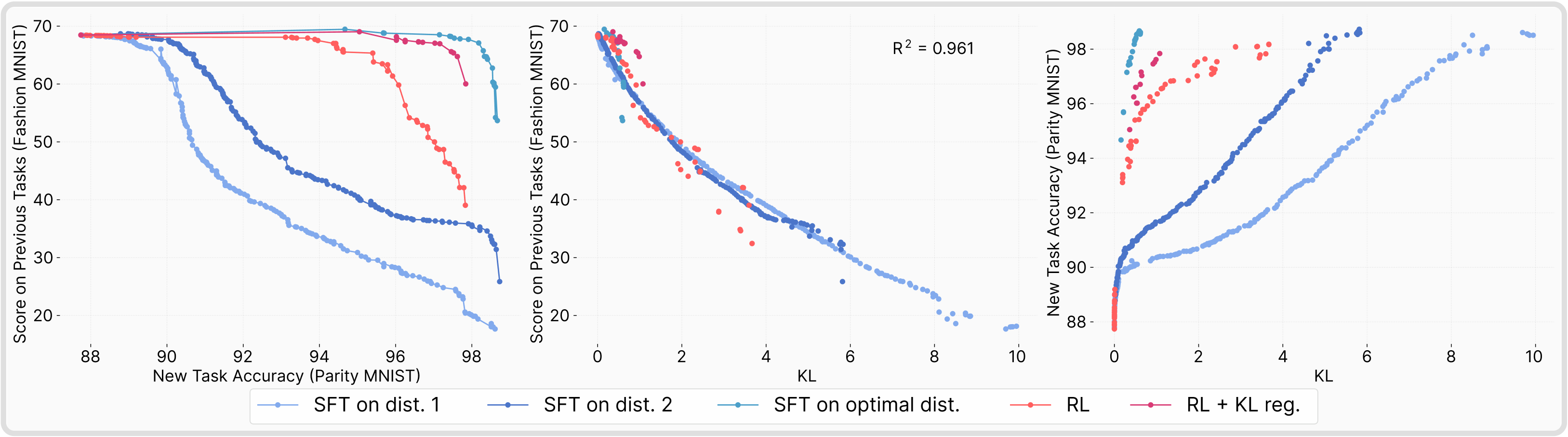
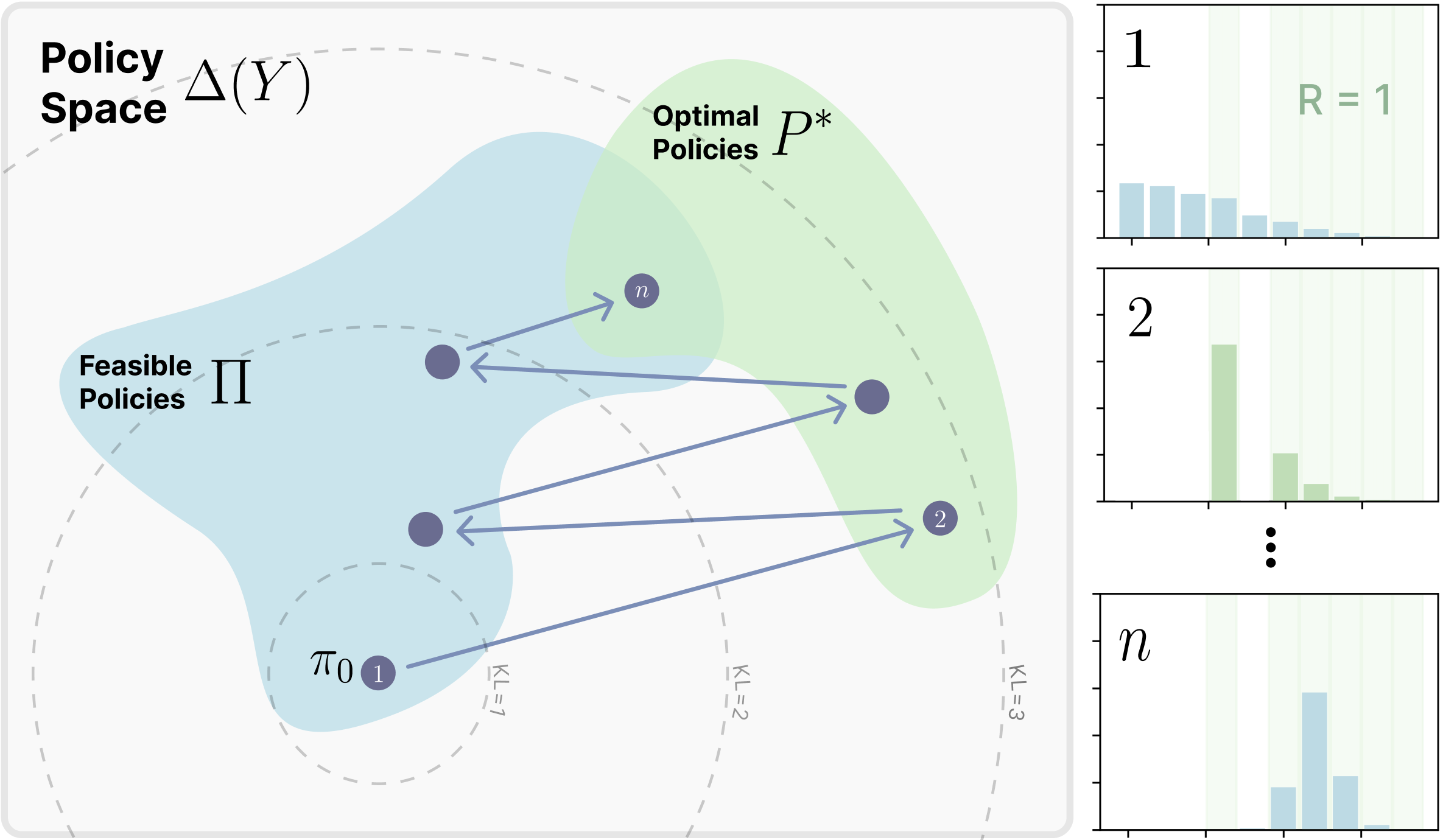
A central question raised by our initial results is why RL fine-tuning tends to forget less than SFT. To address this, we sought a confounding variable that could robustly explain the behavior of both methods. We systematically tested several candidates, including weight change under different norms, sparsity, and gradient rank. None of these explained the observed differences. What ultimately emerged is that the KL divergence between the trained model and the base model on the new task distribution is an excellent predictor of catastrophic forgetting.
On-policy methods leads to smaller KL divergence
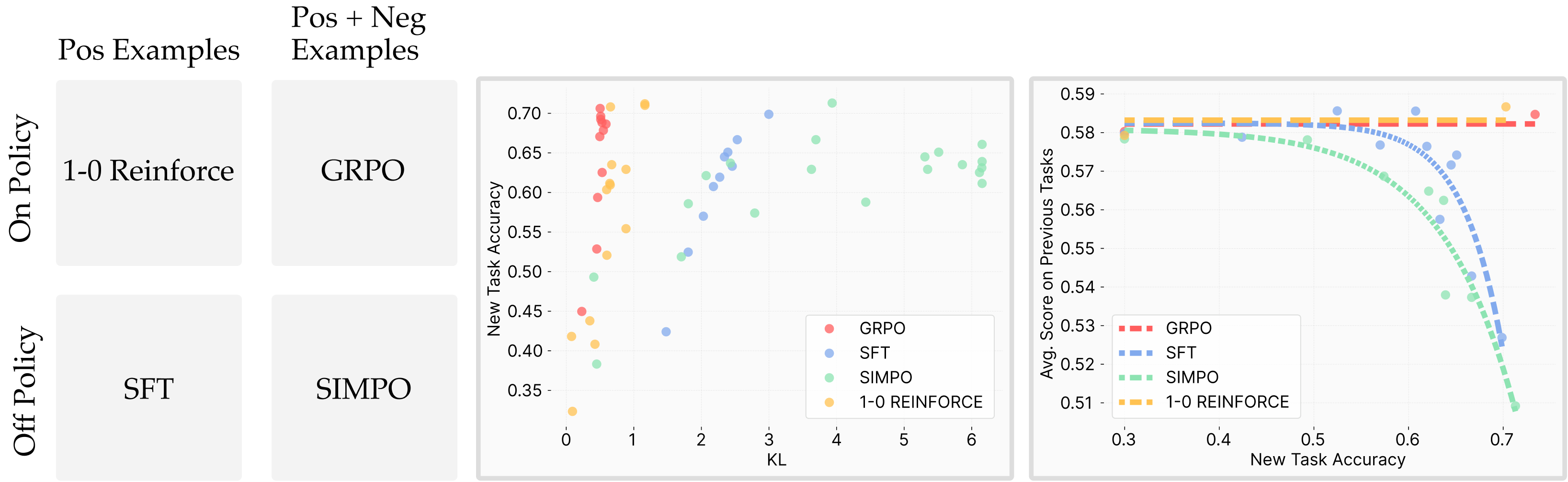
Having established that the KL divergence between the trained model and its base distribution on the new task predicts catastrophic forgetting, we now ask: why are RL fine-tuned models able to achieve strong task performance while moving less in KL than SFT models? Here we see that On-policy methods have the least amount of forgetting. Why is that the case, read below 👇!
Theoretical Perspective
Policy gradient methods can be understood as a form of conservative projection. At each step, the policy samples outputs it already finds likely, then re-weights those samples according to reward, shifting probability mass toward higher-reward outcomes while suppressing lower-reward ones. Crucially, because updates are defined relative to the model’s own distribution, they nudge the policy toward a nearby re-weighted distribution, rather than pulling it toward a potentially distant external distribution (as in SFT). This explains why policy gradient methods tend to remain close to the base model in KL divergence. See our paper for the theorem details!
Bibtex
@misc{shenfeld2025rlsrazoronlinereinforcement,
title={RL's Razor: Why Online Reinforcement Learning Forgets Less},
author={Idan Shenfeld and Jyothish Pari and Pulkit Agrawal},
year={2025},
eprint={2509.04259},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2509.04259},
}