Self-Adapting Language Models
Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim, Pulkit Agrawal
MIT
Paper: https://arxiv.org/abs/2506.10943
Code: https://github.com/Continual-Intelligence
Abstract
Large language models (LLMs) are powerful but static; they lack mechanisms to adapt their weights in response to new tasks, knowledge, or examples. We introduce Self-Adapting LLMs (SEAL) 🦭, a framework that enables LLMs to self-adapt by generating their own finetuning data and update directives. Given a new input, the model produces a self-edit — a generation that may restructure the information in different ways, specify optimization hyperparameters, or invoke tools for data augmentation and gradient-based updates. Through supervised finetuning (SFT), these self-edits result in persistent weight updates, enabling lasting adaptation. To train the model to produce effective self-edits, we use a reinforcement learning loop, using the downstream performance of the updated model as the reward signal. Unlike prior approaches that rely on separate adaptation modules or auxiliary networks, SEAL directly uses the model's generation to parameterize and control its own adaptation process. Experiments on knowledge incorporation and few-shot generalization show that SEAL is a promising step toward language models capable of self-directed adaptation in response to new data.

Method

SEAL is a framework that enables language models to generate their own finetuning data and optimization instructions—called self-edits—in response to new tasks or information. SEAL learns to generate these self-edits via reinforcement learning (RL), using downstream task performance after a model update as the reward. Each training iteration involves the model generating a self-edit based on a task context, applying the self-edit via supervised finetuning, evaluating the updated model, and reinforcing edits that improve performance. This process is implemented with a lightweight reinforcement learning algorithm called ReST, which does rounds of selecting high-reward samples using rejection sampling and reinforcing via SFT. We demonstrate SEAL in two domains: (1) Knowledge Incorporation, where the model integrates new factual information by generating logical implications as synthetic data, and (2) Few-Shot Learning, where the model autonomously selects data augmentations and training hyperparameters to adapt to new abstract reasoning tasks.

Experiments
We test SEAL on two domains:
Knowledge incorporation, where the task is to finetune the model to internalize new factual information from a given passage such that it can answer related questions without access to the original context.

Few-shot learning on ARC, where the model must generalize from a small number of demonstrations by generating its own data augmentations and training configurations to solve abstract reasoning tasks. Here are visuals of both setups.
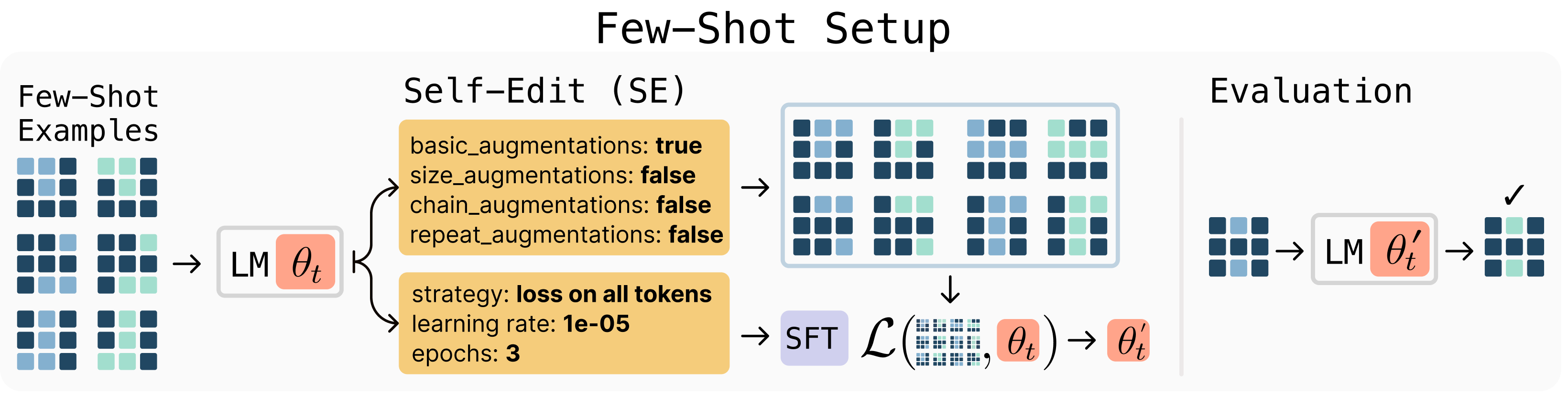
Results
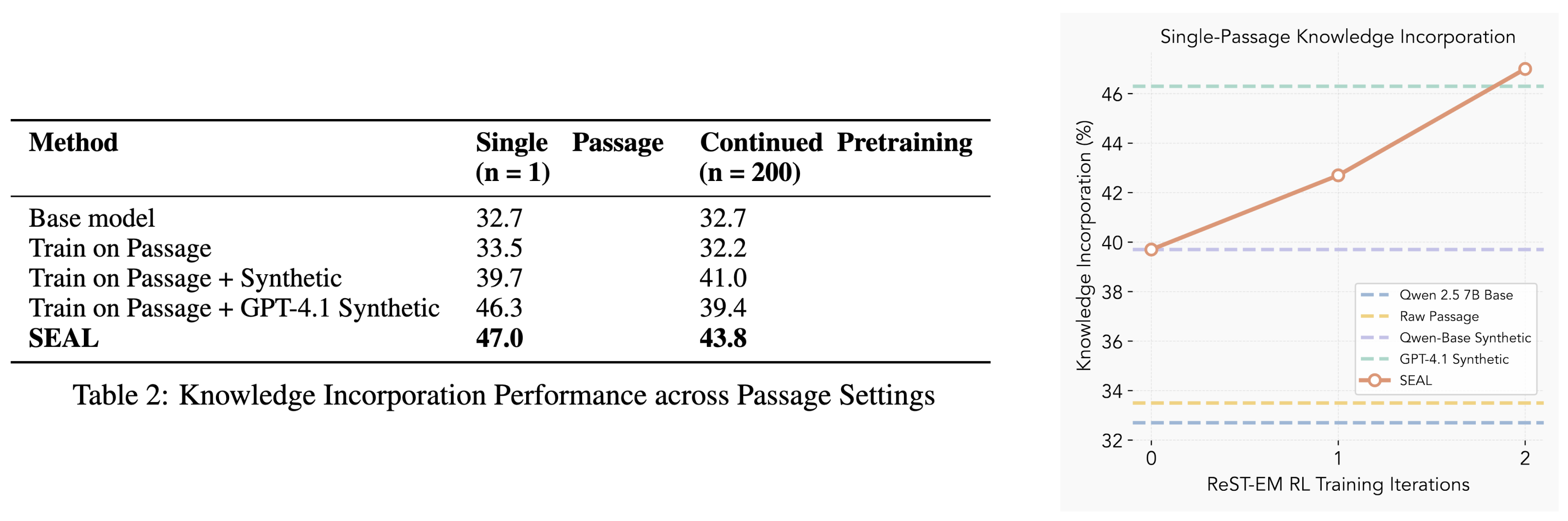
Knowledge Incorporation: We evaluate SEAL on the task of assimilating factual knowledge from textual passages. In the single-passage setting, after two rounds of ReST-EM, SEAL improves QA accuracy from 32.7% (no adaptation) to 47.0%, outperforming models finetuned on raw passages or synthetic data generated by GPT-4.1. In the continued pretraining setting with 200 passages, SEAL again achieves the highest performance at 43.8%, indicating that its learned editing policy scales beyond the single-passage setup in which it was RL-trained. These results highlight SEAL's ability to convert unstructured text into finetuning data that yields lasting and efficient knowledge integration.
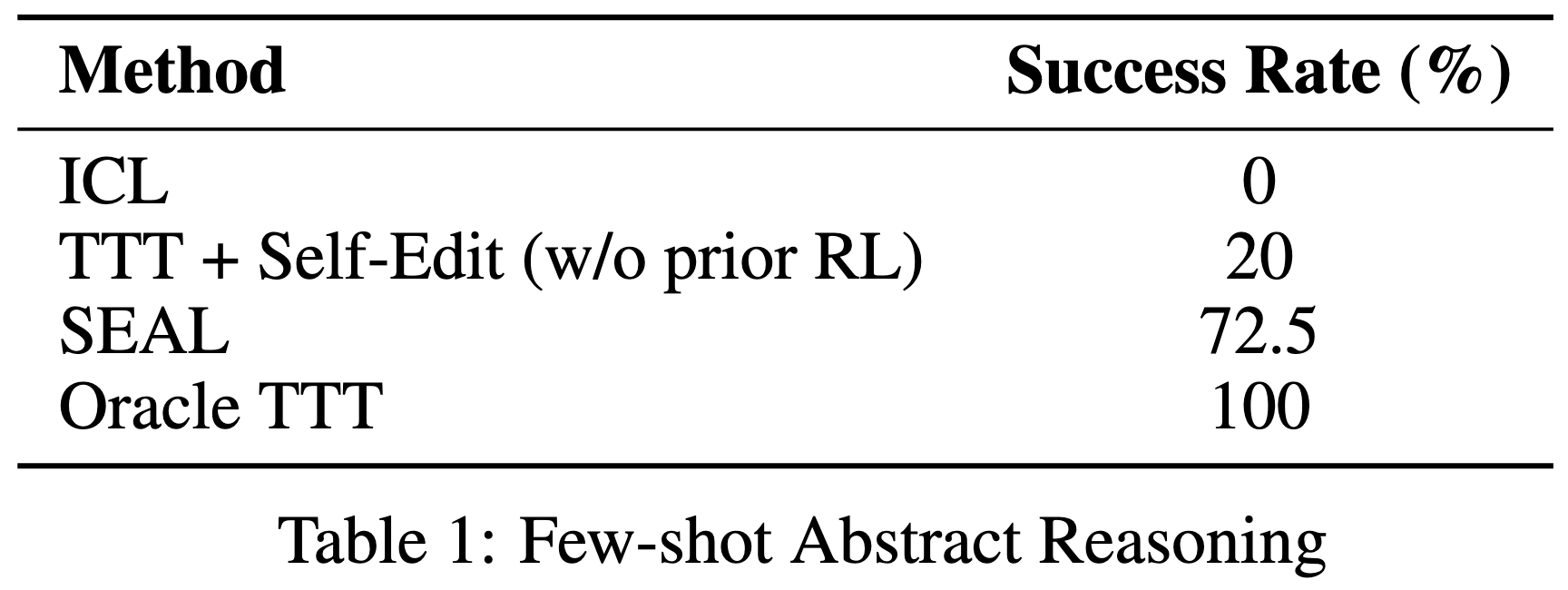
Few-Shot Learning: On a simplified subset of the ARC benchmark, SEAL achieves a 72.5% success rate, significantly outperforming both in-context learning (0%) and test-time training with untrained self-edits (20%). This demonstrates SEAL's ability to learn how to configure augmentations and training strategies autonomously, enabling robust generalization from limited demonstrations.
Limitations
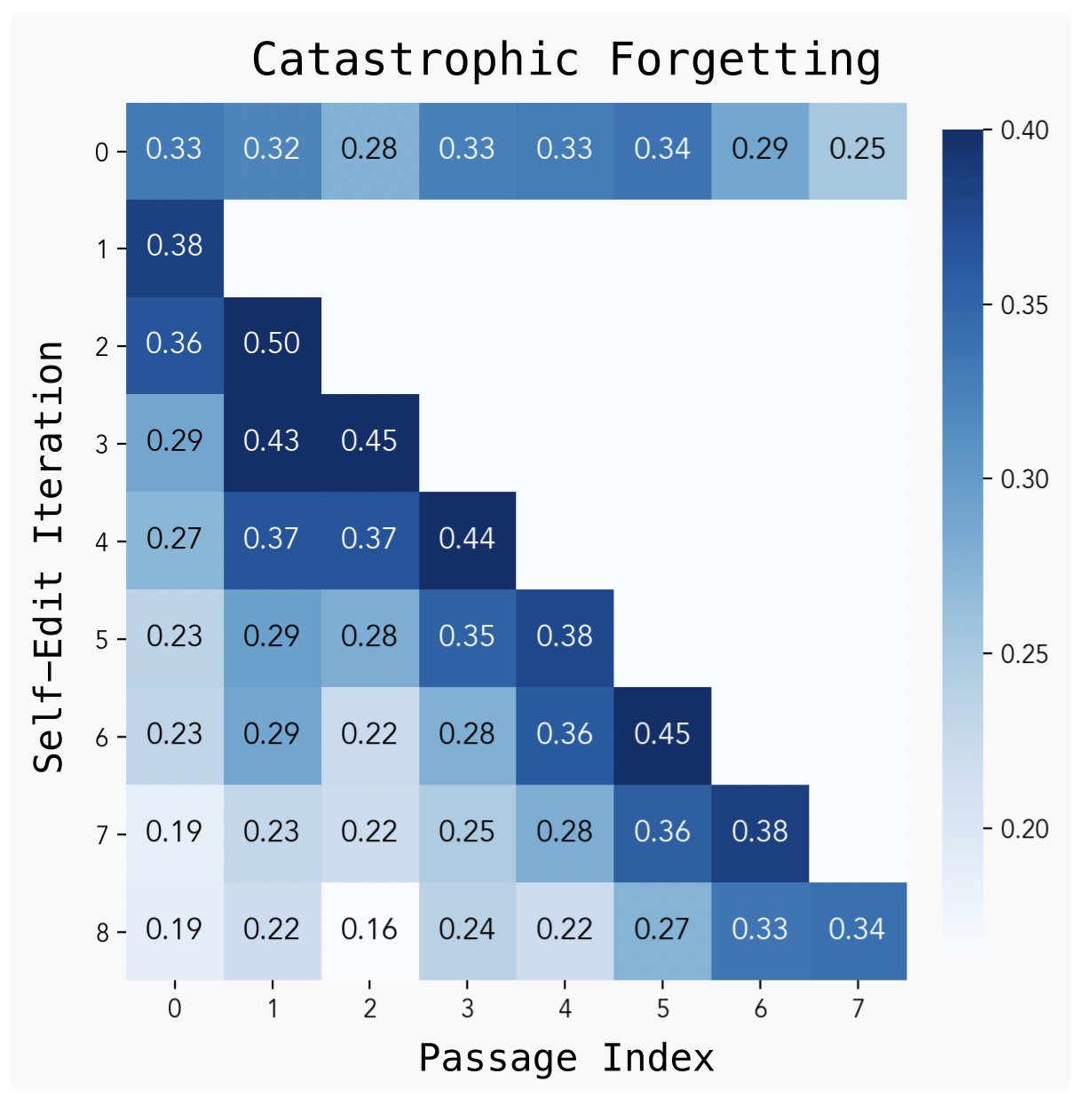
While SEAL enables lasting adaptation through self-generated weight updates, our continual learning experiment reveals that repeated self-edits can lead to catastrophic forgetting—performance on earlier tasks degrades as new updates are applied. This suggests that without explicit mechanisms for knowledge retention, self-modification may overwrite valuable prior information. Addressing this remains an open challenge, with potential solutions including replay, constrained updates, or representational superposition.
Future Work
Looking ahead, we envision models that not only adapt their weights but also reason about when and how to adapt, deciding mid-inference whether a self-edit is warranted. Such systems could iteratively distill chain-of-thought traces into weights, transforming ephemeral reasoning into permanent capabilities, and offering a foundation for agentic models that improve continuously through interaction and reflection.
Bibtex
@misc{zweiger2025selfadaptinglanguagemodels,
title={Self-Adapting Language Models},
author={Adam Zweiger and Jyothish Pari and Han Guo and Ekin Akyürek and Yoon Kim and Pulkit Agrawal},
year={2025},
eprint={2506.10943},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2506.10943},
}