Method Overview
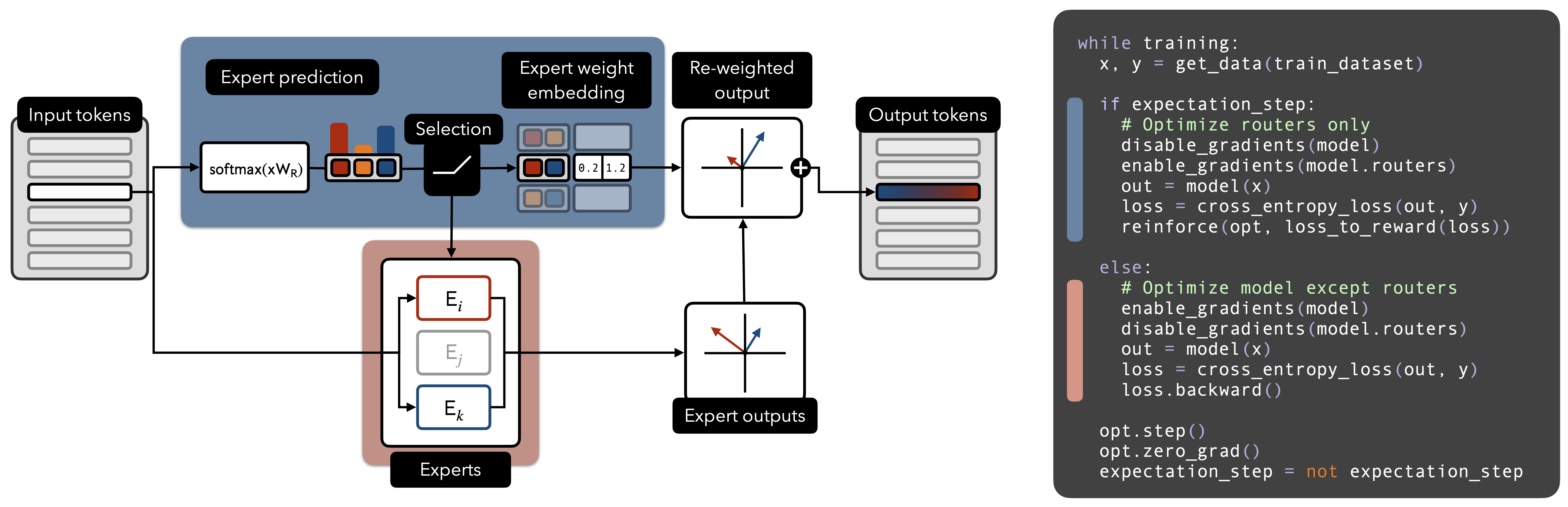
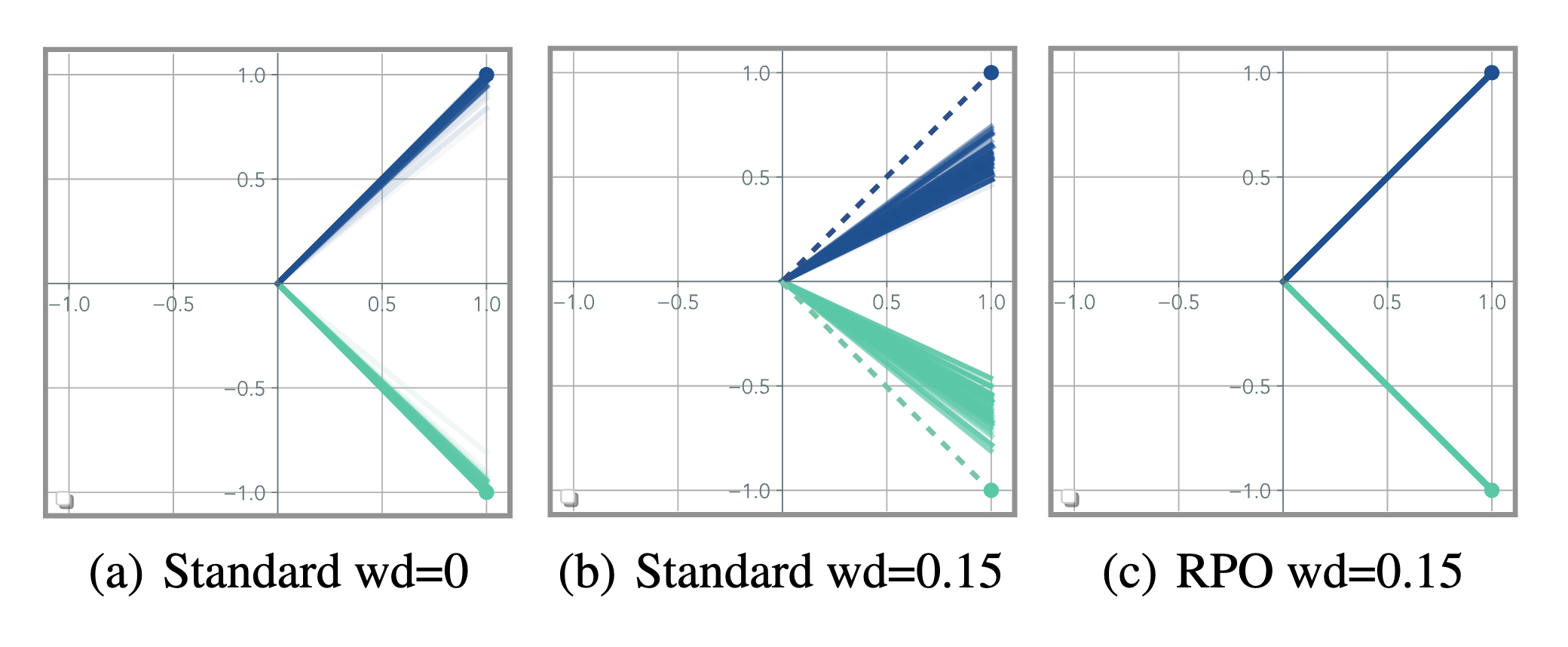
We present Router Policy Optimization (RPO), a novel training mechanism for MoE within transformer models, structured in two distinct phases: router policy optimization (blue) and expert optimization (red). In the router policy optimization phase, input tokens are directed through a router policy, which determines the subset of experts to utilize. The output from these selected experts is then weighted and aggregated. The accompanying pseudocode details our alternating training algorithm, where the expectation step updates the router policy using reinforcement learning, focusing solely on router parameters. The maximization step updates the rest of the model parameters, excluding the routers’. By applying this alternative EM approach, RPO adeptly addresses the intricacies of expert collapse and the balancing of expert contributions, leading to more precise and efficient routing that significantly improves model performance.
.png)